

La loro funzione è sempre più cruciale sia in campo commerciale che scientifico, ricoprono un ruolo oramai imprescindibile per l’analisi di una quantità sempre più crescente di dati grezzi, per la definizione di strategie commerciali o per l’elaborazione di calcoli particolarmente complessi e articolati.
Big Data: Definizione, Caratteristiche e Impatto
I Big Data rappresentano una vera e propria rivoluzione nell’era digitale. Con la loro enorme mole di dati, offrono nuove opportunità per ottenere informazioni preziose e migliorare decisioni aziendali. Secondo Gartner, i Big Data sono risorse informative con elevate caratteristiche di volume, varietà e velocità1.

I Big Data sono una risorsa fondamentale per le aziende che desiderano crescere e prosperare nell’era digitale. L’analisi di queste informazioni può portare a una migliore comprensione del mercato, dei clienti e delle proprie operations, favorendo decisioni più efficienti e innovative.
Secondo la definizione di Gartner, “Big Data” si riferisce a risorse informative che hanno un volume, una varietà e una velocità di produzione così elevate che richiedono tecnologie e metodi di analisi specifici per ottenere un valore numerico o informazioni che non si conoscevano precedentemente.
L’evoluzione dell’analisi dei dati
Per apprezzare la loro importanza e l’ordine di grandezza, bisogna considerare che fino a qualche anno fa, un operatore avrebbe dovuto utilizzare computer mainframe costosi per analizzare una quantità di dati significativamente inferiore agli standard odierni.
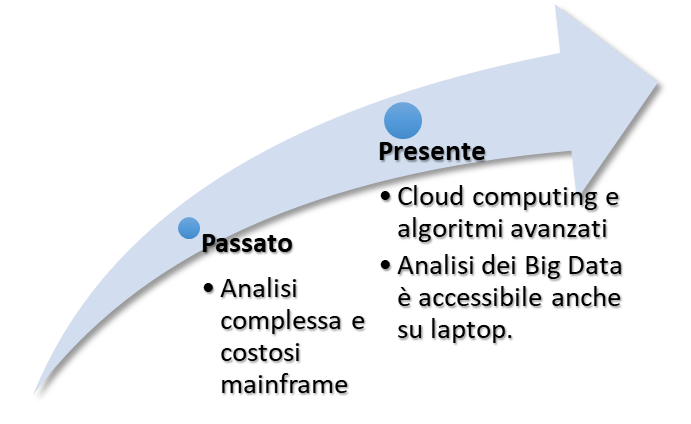
Oggi, con un semplice laptop con accesso alla piattaforma di analisi residente nel cloud, la stessa quantità di informazioni può essere analizzata con un semplice algoritmo in poche ore.
Benefici dei Big Data
L’analisi di queste informazioni può favorire decisioni più efficienti e innovative perché i Big Data aiutano a scoprire nuove informazioni e tendenze che non sarebbero visibili con dati di dimensioni ridotte.
L’analisi dei Big Data permette di prendere decisioni più informate e strategiche offrendo, alle organizzazioni che li sfruttano, un vantaggio competitivo rispetto ai concorrenti.

Il Data Mining: Estrazione di conoscenza da grandi volumi di dati
Data mining è il processo di estrapolazione di informazioni di varia natura, effettuate su grandi banche dati, singole o multiple, le quali vengono correlate per ottenere informazioni più accurate in tempi sempre più ridotti.

Il Data Mining non si limita a una semplice analisi di dati, ma rappresenta un vero e proprio processo di scoperta. Attraverso algoritmi avanzati e tecniche statistiche, si identificano modelli, correlazioni e tendenze nascoste nei dati, fornendo informazioni che altrimenti non sarebbero evidenti.
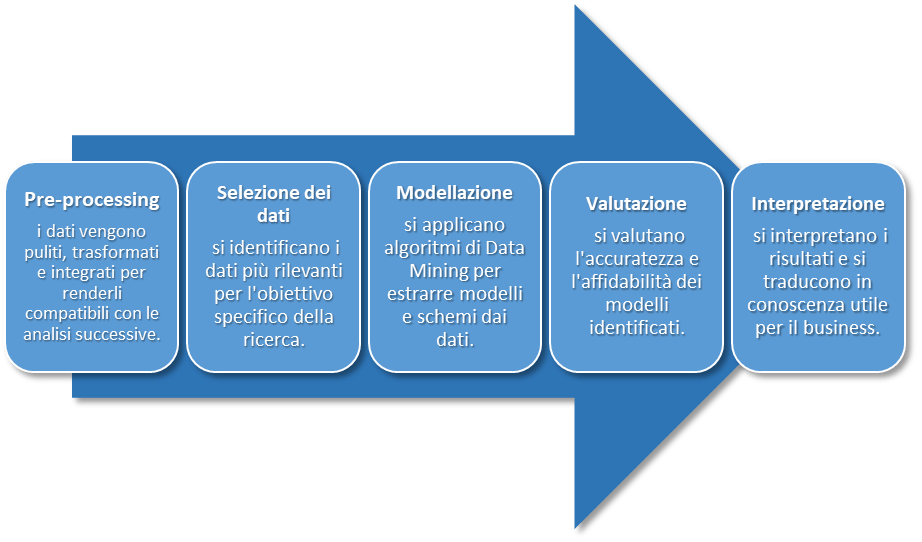
Il Data Mining offre considerevoli vantaggi alle nostre organizzazioni: dalla migliore comprensione dei clienti e delle dinamiche di mercato, all’ottimizzazione dei processi produttivi alla riduzione dei costi per una maggiore redditività degli investimenti. Tuttavia presenta potenziali criticità connesse con la grande mole di dati da gestire, la complessità degli algoritmi (che richiedono competenze specifiche) e potenziali rischi per la privacy e la sicurezza dei dati.
Che cos’è il Machine Learning
La parola “machine learning” si riferisce alla “sfera” scientifica relativa alla capacità di creare algoritmi e modelli statistici, che vengono utilizzati dai sistemi informatici per svolgere compiti senza fornire direttamente istruzioni e utilizzando invece modelli e procedimenti di inferenza[1] .
In altri termini è la capacità dei sistemi informatici di apprendere e migliorare autonomamente le proprie prestazioni, basandosi su dati e algoritmi2. Invece di fornire istruzioni esplicite, il ML insegna ai sistemi a “imparare” dai dati, identificando modelli e relazioni che permettono di fare previsioni e prendere decisioni più precise.

Gli algoritmi di ML sono utilizzati dai sistemi informatici per identificare modelli di dati e elaborare grandi volumi di dati. Questo gli consente di elaborare delle predizioni sui risultati in modo più preciso partendo da un set di dati predeterminato. Gli analisti, ad esempio, possono “addestrare” un’applicazione medica per la diagnosi di una specifica patologia, utilizzando le radiografie, analisi ematiche e ogni dato biomedico del paziente, archiviando milioni di immagini e parametri medici, facendo sì che venga sviluppata una diagnosi appropriata.
Integrazione con l’AI: un binomio inscindibile per il futuro
La combinazione di queste tecnologie va “a braccetto” con il concetto di Intelligenza Artificiale che si riferisce a sistemi o macchine che imitano l’intelligenza umana. Sebbene le parole “machine learning” e “intelligenza artificiale” siano spesso associate, non hanno esattamente lo stesso significato. Una differenza significativa è che l’intelligenza artificiale non include solo il machine learning, anche se comprende tutto ciò che riguarda il machine learning. L’intelligenza artificiale (IA) è dunque l’abilità di una macchina di esprimere capacità umane come la creatività, il ragionamento, l’apprendimento e la pianificazione.

Il sistema che utilizza l’intelligenza artificiale può agire per raggiungere un obiettivo specifico, comprendere il proprio ambiente, relazionarsi con ciò che percepisce e risolvere problemi. I dati, che sono stati già preparati o raccolti tramite sensori come ad esempio una videocamera, vengono ricevuti dal computer, che li processa e risponde. L’analisi degli effetti delle azioni svolte, in un tempo “x” precedente, consente ai sistemi di intelligenza artificiale (IA) di adattare il proprio comportamento.
Esempio pratico: segmentazione dei clienti con il Machine Learning
Immaginiamo un’azienda di cosmetici che desidera lanciare una nuova linea di prodotti anti-età. L’obiettivo è raggiungere i clienti più propensi ad acquistare questo tipo di prodotto.
In passato:
- L’azienda si sarebbe basata su dati demografici (età, sesso) e geografici per identificare il target.
- La segmentazione sarebbe stata generica e poco precisa.
- Le campagne di marketing avrebbero avuto un’efficacia limitata.
Con il machine learning:
- L’azienda può utilizzare algoritmi di clustering[2] per analizzare dati di acquisto, storico di navigazione, interazioni sui social media e preferenze di prodotto.
- I clienti vengono suddivisi in gruppi omogenei (cluster) in base a caratteristiche e comportamenti simili.
- Vengono creati profili dettagliati per ciascun cluster, identificando le loro esigenze e interessi specifici.
- L’azienda può sviluppare campagne di marketing personalizzate e mirate per ogni cluster, offrendo il prodotto giusto al cliente giusto al momento giusto.
I vantaggi del nuovo approccio riguardano la ,aggiore efficacia delle campagne di marketing, un aumento del ritorno sull’investimento (ROI), una migliore soddisfazione del cliente con conseguente fidelizzazione.
In conclusione, il ML offre un approccio innovativo alla segmentazione dei clienti, consentendo alle aziende di creare campagne di marketing più precise e personalizzate. L’esempio sopracitato illustra solo uno dei tanti modi in cui questa tecnologia può essere utilizzata per migliorare le strategie di marketing e raggiungere i clienti con maggiore efficacia.
Le potenziali minacce
Il Comitato Consultivo della Convenzione sulla Protezione delle Persone rispetto al Trattamento Automatizzato di Dati a Carattere Personale (Convenzione 108[3]) ha sottolineato che un’innovazione responsabile nel settore dell’intelligenza artificiale richiede un approccio incentrato sulla prevenzione e sull’eliminazione dei potenziali rischi del trattamento dei dati personali.
Per ridurre la quantità di dati personali trattati dalle applicazioni di intelligenza artificiale, l’utilizzo di dati sintetici può rappresentare una soluzione per evitare che le informazioni siano riconducibili ai soggetti a cui si riferiscono e superare gli ostacoli all’innovazione tecnologica posti dalla normativa vigente sulla protezione dei dati personali.
I dati sintetici, così definiti perché sono stati ottenuti attraverso un processo di sintetizzazione, sono informazioni fittizie che vengono ottenute utilizzando algoritmi di apprendimento automatico di tipo generativo da dati reali. L’algoritmo è stato formato per replicare le caratteristiche e la struttura dei dati originali, il che gli consente di ottenere risultati statisticamente accurati.
Tali dati devono essere tuttavia trattati in conformità con le leggi sulla protezione dei dati personali, perché vengono ottenuti partendo da informazioni reali, nonostante la loro natura artificiale.
Questo aspetto, deve essere pertanto tenuto presente prima della fase di raccolta delle informazioni per il processo di sintetizzazione. Quando si scelgono o si ottengono le informazioni che l’algoritmo di machine learning dovrà sintetizzare, è necessario garantire che le leggi sulla protezione dei dati personali siano rispettate. In particolare, è necessario assicurarsi che le persone siano adeguatamente informate sulle finalità del trattamento dei loro dati, che abbiano la possibilità di mantenere il controllo su come vengono utilizzati e che questo utilizzo sia basato su un’adeguata base giuridica.
Il livello di maturità nelle aziende italiane dell’utilizzo delle tecnologie connesse ai Big Data
Secondo uno studio dell’Osservatorio Big Data & Business Analytics della School of Management del Politecnico di Milano del 2023, la spesa in questo settore ha registrato un aumento del 18% rispetto all’anno precedente, in un mercato dei BIG DATA a livello nazionale dal valore 2,85 miliardi di euro, dove l’83% degli investitori è composto da grandi imprese, mentre il 17% è composto da microimprese e PMI.
Cresce la capacità complessiva delle grandi aziende di utilizzare i dati, infatti secondo il Data Strategy Index, il valore medio dell’indice migliora leggermente e la percentuale di aziende di livello avanzato cresce, raggiungendo il 20% nel 2023 dal 15% nel 2022.
Tuttavia, un terzo delle grandi aziende italiane (32%) è ancora immaturo o in fase di avvio e pertanto, la strada di una diffusa implementazione delle summenzionate tecnologie è ancora lunga e merita un’attenta promozione e valorizzazione, nel rispetto delle vigenti normative di protezione dei dati personali.
In estrema sintesi le aziende italiane investono sempre di più nei Big Data, ma c’è ancora molta strada da fare per una diffusione completa e matura.
[1] (procedimento statistico di generalizzazione dei risultati ottenuti attraverso una rilevazione parziale per campioni all’intera popolazione da cui è stato estratto il campione. Def. Oxford Languages)
[2] In statistica, il clustering o analisi dei gruppi (dal termine inglese cluster analysis, introdotto da Robert Tryon nel 1939) è un insieme di tecniche di analisi multivariata dei dati volte alla selezione e raggruppamento di elementi omogenei in un insieme di dati. (fonte wikipedia.org)
[3] Consultative committee of the convention for the protection of individuals with regard to automatic processing of personal data (convention 108) – guidelines on artificial intelligence and data protection. (fonte. Council of Europe https://rm.coe.int/guidelines-on-artificial-intelligence-and-data-protection/168091f9d8)
- Volume: La quantità di dati generati è in continua crescita, richiedendo tecnologie specifiche per la gestione e l’analisi.
Varietà: I dati provengono da diverse fonti, strutturate e non strutturate, come social media, sensori, transazioni e log.
Velocità: I dati vengono generati e analizzati in tempo reale, consentendo un’analisi immediata e decisioni più rapide. ↩︎ - Algoritmi: Esistono diversi tipi di algoritmi di ML, ognuno con caratteristiche e scopi specifici. Tra i più comuni troviamo:
Apprendimento supervisionato: l’algoritmo viene “istruito” su un set di dati con esempi già classificati, in modo da imparare a classificare nuovi dati.
Apprendimento non supervisionato: l’algoritmo identifica autonomamente modelli e relazioni nei dati, senza esempi predefiniti.
Apprendimento per rinforzo: l’algoritmo impara a svolgere un compito attraverso prove ed errori, ricevendo un feedback positivo o negativo in base alle sue azioni. ↩︎

Lascia un commento